Batch generation of font preview images with multicore processing
Abstract
Our video generation service RICHKA enables users to customize image/video materials and texts, fonts, BGM, color schemes and the latter video generations are run with the configurations.
In this post, we introduce a background processing of the font customizing feature, especially auto generation of preview font images actually rendered by the underlying font engine with font files installed on the OS with multi-core processing. If the number of the fonts is few around 10, it is possible to manually create them with taking screenshots and cropping desired areas and save as image file. However, our video servers have over 1000 fonts and it is still increasing and difficult to do by hand. To resolve such cases, a batch processing helps us, but high speed techniques become also important.
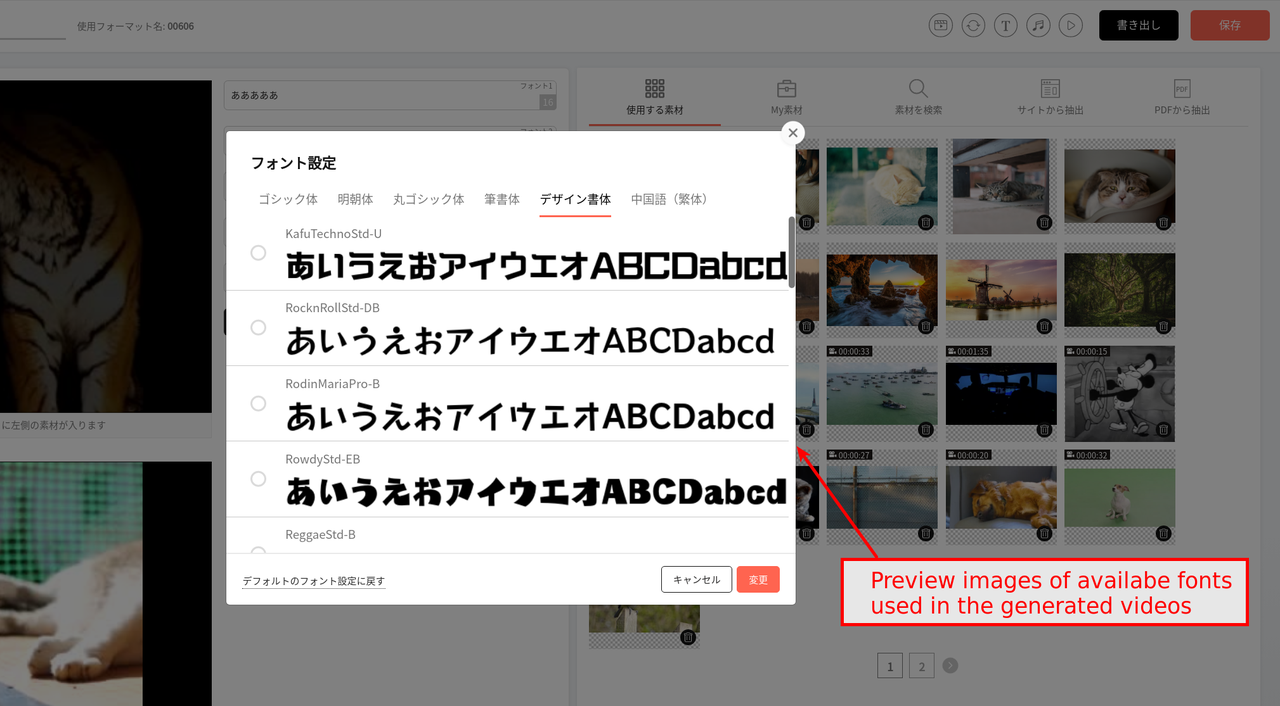
The generated preview images are actually shown on the GUI below and users can visually select desired fonts used for the video generation. The whole source code is also introduced and with utilizing some convenient Linux commands as this script, we can implement in short time.
Multi-core processing
On RICHKA video servers, the number of installed fonts are over 1000 and it takes much time to execute with sequential batch processing to generate the font preview images. However, we can shorten the heavy processing with applying multi-core processing to generate them in parallel because each processing is independent each other and it is general to have multi-core CPU these days.
The multi-core processing is easy thanks to Python3 builtin package multiprocessing. The excerpt of a sample program below is to call gen_preview_image with multi-core CPU. When it has prepared 100 data sets, they are executed in parallel. In this example, the max number of the used CPU core at a time is 1 less number than the number of CPU cores. The result values returned from the function gen_preview_image are accumulated and we can get all of the results as well.
def process_multicore(func_ptr, dset):
import multiprocessing as multi
p = multi.Pool(multi.cpu_count() - 1) # max number of processes
result = p.starmap(func_ptr, dset)
p.close()
p.join()
return result
def run_all(fontdir, outdir, is_overwrite=False):
# init
if not os.path.exists(outdir):
os.mkdir(outdir)
fontfiles = [f for f in glob.glob(fontdir + "**/*.*", recursive=True)]
dset = []
results = []
for fontfile in fontfiles:
dset.append((fontfile, outdir, is_overwrite))
if len(dset) > 100:
res = process_multicore(gen_preview_image, dset)
results.extend(res)
dset = []
if len(dset):
res = process_multicore(gen_preview_image, dset)
results.extend(res)
return results
if __name__ == '__main__':
logging.basicConfig(level=logging.DEBUG)
fontDirs = [f'/usr/share/fonts/']
results = []
for fontDir in fontDirs:
result = run_all(fontDir, f'/home/{getpass.getuser()}/tmp/font_images/')
results = results + result
print(json.dumps(results))
Sample program
The whole source code is below and we use convert command of ImageMagic to generate font preview images. The images are actually rendered by a font engine of the OS such as FreeType. The rendered characters are 'あいうえおアイウエオABCDabcd' in default including Japanese, but some of fonts don't have the Japanese griph data, then 'ABCDEFGabcdefg' is rendered as fallback.
#!/usr/bin/env python
import logging
import getpass
import glob
import json
import os
import shutil
import sys
import subprocess
from fontTools import ttLib
def shortName(font):
"""Get the short name from the font's names table"""
name = ""
for record in font['name'].names:
if b'\x00' in record.string:
name = record.string.decode('utf-16-be')
else:
name = record.string.decode('utf-8', 'surrogateescape')
return name
def gen_preview_image(fontfile, outdir, is_overwrite=False, pointsize=40, text='あいうえおアイウエオABCDabcd', ascii_text='ABCDEFGabcdefg', fname_prefix=''):
try:
ttf = ttLib.TTFont(fontfile, fontNumber=0) # https://github.com/fonttools/fonttools/issues/541
font_name = shortName(ttf)
fname_out = os.path.join(outdir, fname_prefix + font_name.replace(' ', '_') + '.png')
cmd = f"convert -font '{fontfile}' -pointsize {pointsize} label:{text} '{fname_out}'"
cmd_in = cmd.encode('utf-8', 'surrogateescape')
if is_overwrite or not os.path.exists(fname_out):
try:
cmd_out = subprocess.getoutput(cmd_in)
except subprocess.CalledProcessError as grepexc:
logging.debug("error and try only with ascii:", grepexc.returncode, grepexc.output, fontfile)
cmd = f'convert -font {fontfile} -pointsize {pointsize} label:{ascii_text} {fname_out}'
cmd_in = cmd.encode('utf-8', 'surrogateescape')
try:
cmd_out = subprocess.getoutput(cmd_in)
except subprocess.CalledProcessError as grepexc:
logging.debug("error :", grepexc.returncode, grepexc.output, fontfile)
fname_out = None
return {'preview_image_path': fname_out, 'name': font_name, 'path_font': fontfile}
except ttLib.TTLibError as e:
logging.debug(e)
return {'preview_image_path': None, 'name': 'UNKNOWN', 'path_font': fontfile}
def process_multicore(func_ptr, dset):
import multiprocessing as multi
p = multi.Pool(multi.cpu_count() - 1) # max number of processes
result = p.starmap(func_ptr, dset)
p.close()
p.join()
return result
def run_all(fontdir, outdir, is_overwrite=False):
# init
if not os.path.exists(outdir):
os.mkdir(outdir)
fontfiles = [f for f in glob.glob(fontdir + "**/*.*", recursive=True)]
dset = []
results = []
for fontfile in fontfiles:
dset.append((fontfile, outdir, is_overwrite))
if len(dset) > 100:
res = process_multicore(gen_preview_image, dset)
results.extend(res)
dset = []
if len(dset):
res = process_multicore(gen_preview_image, dset)
results.extend(res)
return results
if __name__ == '__main__':
logging.basicConfig(level=logging.DEBUG)
fontDirs = [f'/usr/share/fonts/']
results = []
for fontDir in fontDirs:
result = run_all(fontDir, f'/home/{getpass.getuser()}/tmp/font_images/')
results = results + result
print(json.dumps(results))
Sample of generated preview images
It took a few minutes to have generated the preview images with over 1000 fonts and the sample ones are below. The processing speed is enough and we can utilize the max of the CPU resources.

Conclusion
We introduced a practical sample program to execute a batch processing to generate font preview images with over 1000 fonts with utilizing multi-core CPU. Though we omitted in the sample code, our video servers stores the generated preview images into S3 and they are actually shown on RICHKA GUI and it helps users to visually select desired fonts used for video generation.