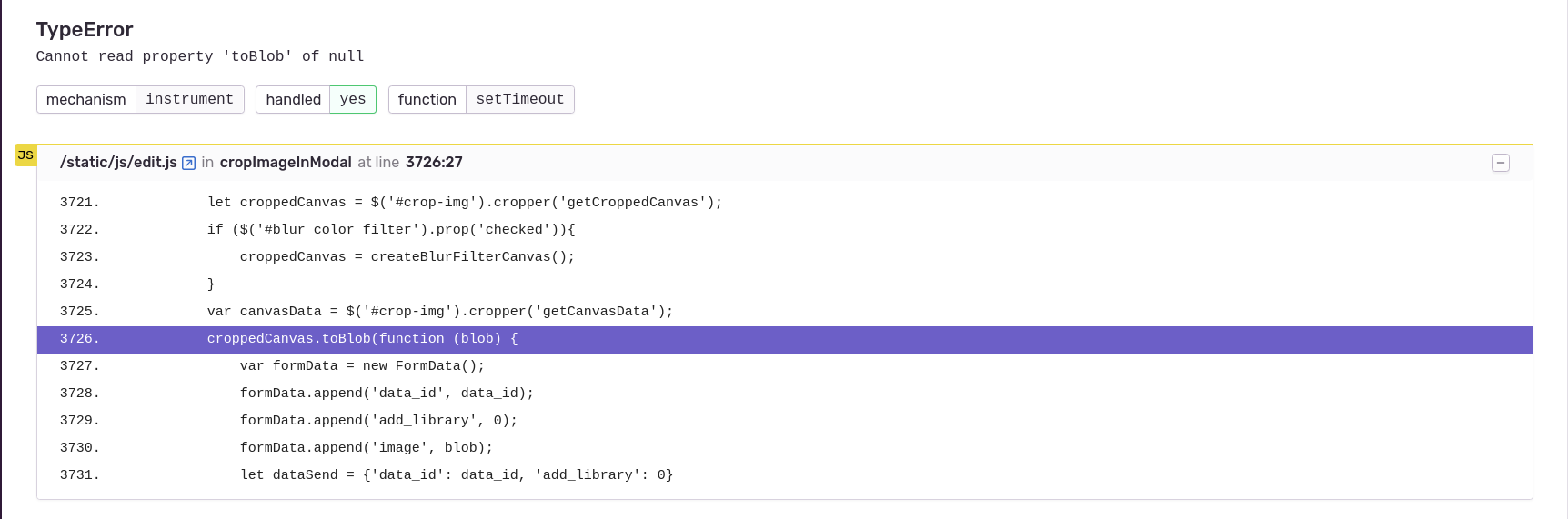
The prototype of Morphing
Abstract
In this post, we introduce HyperMorph on HTML5 that allow us to create motions of objects and then export these motions into video files.
Definitions
Morphing
Morphing is a special effect in motion pictures and animations that change (or morphs) one image or shape into another through a seamless transition. Traditionally such a depiction would be achieved through dissolving techniques on film. Since the early 1990s, this has been replaced by computer software to create more realistic transitions. A similar method is applied to audio recordings in similar fashion, for example, by changing voices or vocal lines.
HyperMorph
There are many terminologies on HyperMorph that you can check on https://blog.altair.co.kr/wp-content/uploads/2011/03/hypermorph.pdf.
Within this post, we just define a simple definition about HyperMorph on video generation. It is a set of points from a 1st image and a corresponding set of points from a 2nd image. A special effect will change two sets together and makes the 1st image become the 2nd image and vice versa. When we define enough of points, it will be able to create very smooth video.
How to create HyperMorph from two images with HTML & JavaScript
- Define the set of points on the 1st image and a corresponding set of points from 2nd image.
- Using HTML5 canvas to draw a shrink image based on moving points between two sets and merge two images.
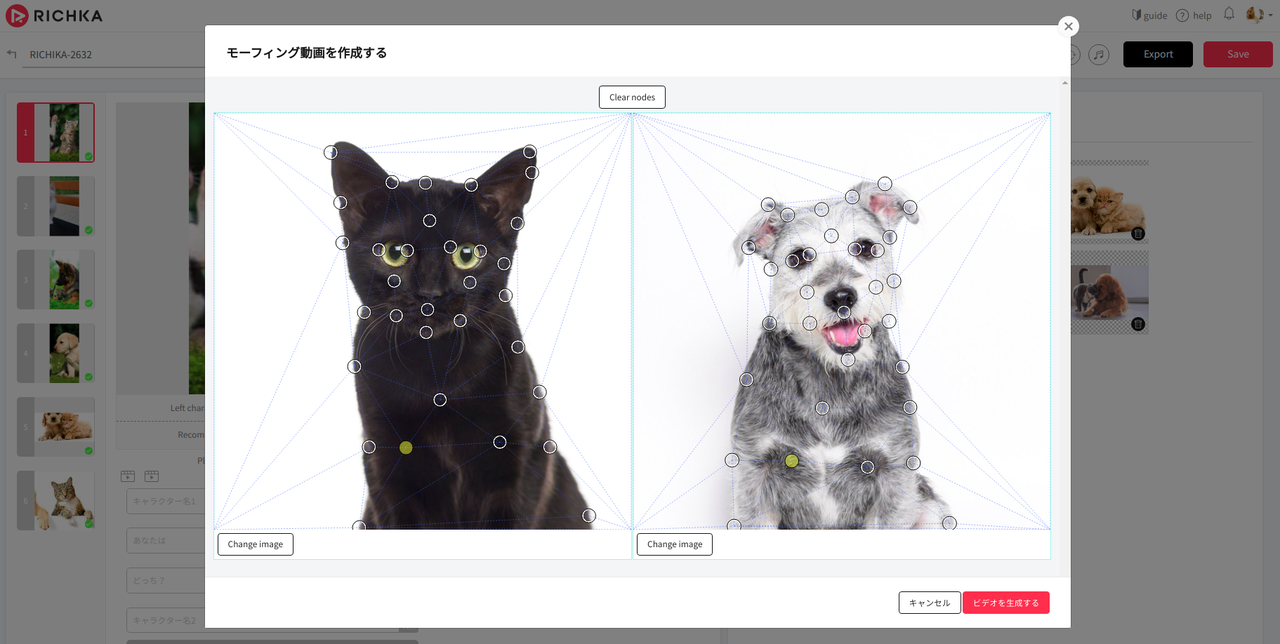
- With each moving step, capture the image on the canvas and add it as a frame of a video.
- When capture enough frames of a video, we can export these frames into a video file.
And here is the output video (I converted to GIF file to display here easily):